NoSQL – Overview
Not only SQL.
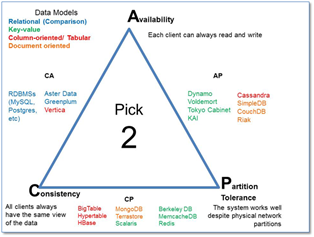
CAP Theorem – Brewer’s Theorem
- Consistency (all nodes see the same data at the same time)
- Availability (a guarantee that every request receives a response about whether it succeeded or failed)
- Partition tolerance (the system continues to operate despite arbitrary message loss or failure of part of the system)
Types of databases
- Relational
- Key-Value
- Column-Oriented
- Document-Oriented
Row-Oriented Databases
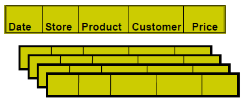
+ Easy to add rows and data
– Might read unnecessary data
Column – Oriented Databases
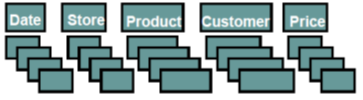
+ only read relevant data
– tuple writes require multiple accesses
Column-Oriented DBs: suitable for read-mostly, read-intensive, large data repositories
Fundamental difference is only in the storage layout – but this has huge implications.
Example – read efficiency
select team from cfb_game; #real-world tables are much much more complex.
Row-Oriented DB returns entire table into memory and then projects on team
Columnar DB reads only the column we need.
Example – compression efficiency
Columns compress better than rows
- Typical row-store compression ratio 1 : 3
- Column-store 1 : 10
Why? 2 minute guess reasons.
Rows contain values from different domains => more entropy, difficult to dense-pack
Columns exhibit significantly less entropy than rows
Example difference in scanning.
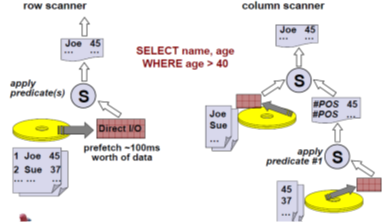
Columnar Optimizer can retrieve data from two different disks at the same time and combine them in the project operator
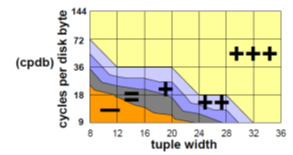
Tradeoffs – as number of columns increases so does the benefits of columnar DBs.
<- Tuple width is in bytes not columns
“Cycles per disk byte” –
accounts for many disks, many CPUs, competing traffic.
- Many CPUs and many disks favors columnar
- Single CPU single disk favors row store.
Row Key
Each Hbase row has to have a rowkey, this ties everything together Can be any type of data, even a complex object
Column Families
Columns in HBase are grouped into column families
Each column family can have multiple rows that are stored together on disk – optimized for compression and storage.
Let’s say you are a Bank and want to make a Person Table
name, address, birthdate, gender, ssn, ethnicity, fica_score, acct balance, height
What column families would you make?
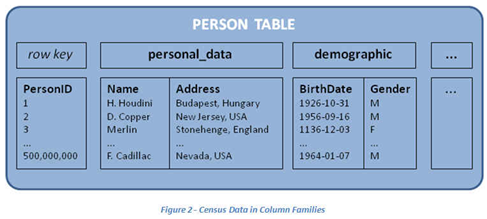
A column family is defined in the table, a column is not – they are defined during insertion
Each value in a column name is a triplet = <column_name, value, timestamp> e.g. ‘cf:col, val’ where cf is called the column family qualifier – “qualifier” because it the text must “qualify” as printable chars.
Hbase on db8
$su hadoop $start-all.sh: hdfs namenode, hdfs datanode $start-hbase.sh: hbase zookeeper start, hbase regionserver start, hbase master start
$hbase shell
>create ‘person’, ‘pd’, ‘d’, ‘b’ //for personaldata, demographics and bank >scan ‘person’ >put 'person', 'row1', 'pd:last_name', 'Tompson’ >scan ‘person’
$ hadoop fs -ls /hbase //to show how the docs are stored
db.cse.nd.edu:9870/hbase/data/default // stores columns as files. Nothing there?!?!
It’s in memstore, we need to flush to disk. This can be done automatically when mem is filled or…
>flush 'person'
db.cse.nd.edu:9870/hbase/data/default
>put 'person', 'row2', pd:last_name', 'Tompson' >put 'person', 'row2', pd:first_name', 'Mary' >scan ‘person’ //now a birthday >put 'person', 'row1', pd:first_name', 'Bob'
| RowKey | timestamp | First_Name | Last_name | ||
|---|---|---|---|---|---|
| row1 | 1 | Tompson | |||
| 4 | Bob | Tompson | |||
| 5 | Bob | Thompson | |||
| Row2 | 2 | Tompson | |||
| 3 | Mary | Tompson |
What does the current database look like in Tuple-Storage format?
>scan ‘person’ // updated with new timestamp – old value kept (depending on configuration)
>get ‘person’, ‘row1’
>get ‘person’, ‘row1’, ‘pd’
>get ‘person’, ‘row1’, ‘pd:first_name’
>put 'person', 'row1', 'pd:last_name', 'Thompson' //lets change Bob’s last name
>scan ‘person’
>scan 'person', {COLUMNS => ['pd'],FILTER => " (SingleColumnValueFilter('pd','first_name',=,'regexstring:M*ry',true,true))"}
>show_filters
>drop ‘person’ //does not work
>disable ‘person’ //do this first
>drop ‘person’