1. 15pts We have created a zips table under the cse30246 database; You should be able to access it via select * from zips limit 10. Use this table to answer the following questions. Make sure that you report the answer the first time you run the query, multiple uses of the same query get treated differently than the first run.
Note: There is no primary key (for educational purposes only – you should always have a primary key in any table), the city and state columns are not indexed and the city_idx column is indexed.
Tip: use the count(*) function, e.g., select count(*) from zips… to keep from returning millions of results for some queries.
Tip: Remember that you can use desc zips; in order to look at the schema of the table.
1a. I expanded the number of zip codes for this assignment. I basically added zeros to the zipcodes to create lots of data. How many rows are in this table?
1b. How long does it take to find the city where the zip code is 46556? Why is it so fast/slow?
Issue this query to get a random city and state.SELECT city, state_id FROM zips ORDER BY RAND() LIMIT 1;
Write down the result – It is important that you use the city from this query in the remainder of problems in Q1 and Q2.
1c. How long does it take to find the zipcode records (from non-index city-column) with the same name as your randomly chosen city? Consider 1b and 1c – Explain the runtime difference, if any.
1d. Now try to find your zip code record using the indexed city_idx column. How long does it take? What is the difference between 1c and 1d? Explain the runtime difference, if any.
1e. For this query, remove the last three letters of your city’s name, for example, if you have ‘South Bend’, query for all records starting with ‘South B’. How long does it take to find all records starting with the first few letters of your city using the non-index city-column? Remember to use the LIKE keyword. Consider 1e and 1c. Why does one take longer than the other?
1f. Now try the same few letters to find the zip code records of your city using the indexed city column. How long does it take? Consider 1f and 1e. Does one take longer than the other? Why?
1g. We could also try to look up cities ending with the last two letters of your city. For example, if your city is ‘South Bend’, you should query for all cities ending with ‘nd’. Using the non-indexed city-column, how long does this take?
1h. Now try using the indexed column city_idx to find cities ending with the same two letters as your city. How long does this take? Compare and explain the runtimes of 1g and 1h. How much does the index help in this circumstance? Why?
1i. Interestingly, zip codes generally decrease from west to east (California has 90000, and New York has 10000). How long does it take to count the zip codes greater than 20000 and less than 80000?
1j. MySql allows lexigraphical ordering of strings (A<B<a<b<c). How long does it take to discover how many cities are “greater” than the full name of your city using the non-index city column?
1k. How long does it take to discover how many cities are greater than the full name of your city using the index city column? Consider 1k and 1j. How much better is the index compared to the non-indexed query? Explain the results.
2. Go work on your project. The best projects are from groups that steadily make progress every week.
3. 15 pts I have also added an industry table into the database called industry_records that contains statistics on the number of companies in a location. This table contains the number of establishments from the Census Bureau https://www2.census.gov/programs-surveys/cbp/technical-documentation/records-layouts/noise-layout/zip_detail_layout.txt and contains items that you can join to the zips table. However, the only way to join these two tables is via the zip column.
For these queries use your city and city’s state. For example,… zips.city_idx = 'South Bend' and zips.state_id = 'IN' and zips.zip <= 99999…
Tip: make sure you include zips.zip < 99999 to remove all the extra data I duplicated for Q1
3a. The zip column has not been indexed on the industry_records table. Using your city and city’s state from Q1 find all of the industrial records that are located on the same zipcode as your city using a query that joins zips with industry_records. How many results does this return? How long did this query take?
3b. The zip_idx column has been indexed on industry_records table. Using your city’s zip code find all of the industrial records that are located on the same zip code as your city. How many results does this return? How long did this query take?
3c. Compare the execution times of 3a and 3b. How big was the difference in execution times? Why?
4. 15pts How does Google use an Index? I used to teach a course on this, and in that course we would make a Google, but we called it the Simple Information Retrieval System (SIRS).
The goal of Q4 is to download, read, and understand how SIRS uses a type of index called an inverted index to answer queries. To start log into db8.cse.nd.edu. In your home directory. Clone SIRS from GitHub, install a virtual environment, and activate it:
git clone https://github.com/tweninger/SIRS.git
cd SIRS
python3 -m venv venv
source ./venv/bin/activateEnsure that:
~/SIRS$ python -V
Python 3.6.8Let’s start by getting a few libraries that are needed by SIRS:
pip install --upgrade pip
pip install scrapy bs4 numpy bitarray flaskThe first goal is to crawl the Web for data. I have a script that does that in ./index/crawler.py Feel free to explore it. Before we begin, we need a place to put the data. Let’s make a data directory:
mkdir dataThen we can start a crawl. By default this crawler starts at http://cse.nd.edu and goes from there. You are welcome to change or add to that list.
python -m index.crawlerThis will run and run and run basically forever. Give it a minute or two to get some data and then use Ctrl+C to kill it. You’ll notice that the data directory now has a tar in it with a bunch of Web pages:
ls -al dataYou can explore that tar file with:
tar -tf data/NDCrawler_result_large.tarTo show the Web pages you just crawled. The next thing to do is create an Inverted Index that maps keywords to the documents:
python -m index.indexerOnce this runs you can look back into the data directory to see the index files.
ls data
anc_idx.txt doc_idx.txt idx.txt NDCrawler_result_large.tar webgraph.txt doc_idx_offset.txt idx_term_offset.txt lex.txt runs Each of these files describes a different part of the index. Take a look through each, print the first line (or two or three depending on how big it is) and describe what each file contains. For example:
(venv) tweninge@db8:~/SIRS$ head data/doc_idx_offset.txt
0
120
242
369
514
635
763
892
1016
1143The doc_idx_offset describes the offset for each document in the doc_idx.txt.
python -m webapp.SIRSYou’ll notice that this probably fails because it, by default, tries to use port 80. So you’ll need to edit the SIRS.py so that it opens another port. I have opened ports 8080-8089 on db8.cse.nd.edu for your use. A port can only be used by one service, so if one fails it may mean that another student is using it.
Keep trying different ports until you find one that is open. Once you find a port that works you will be able to browse to db8.cse.nd.edu:8080 (or whatever port). And you’ll see the SIRS search engine.
Issue a query and describe your first few results:
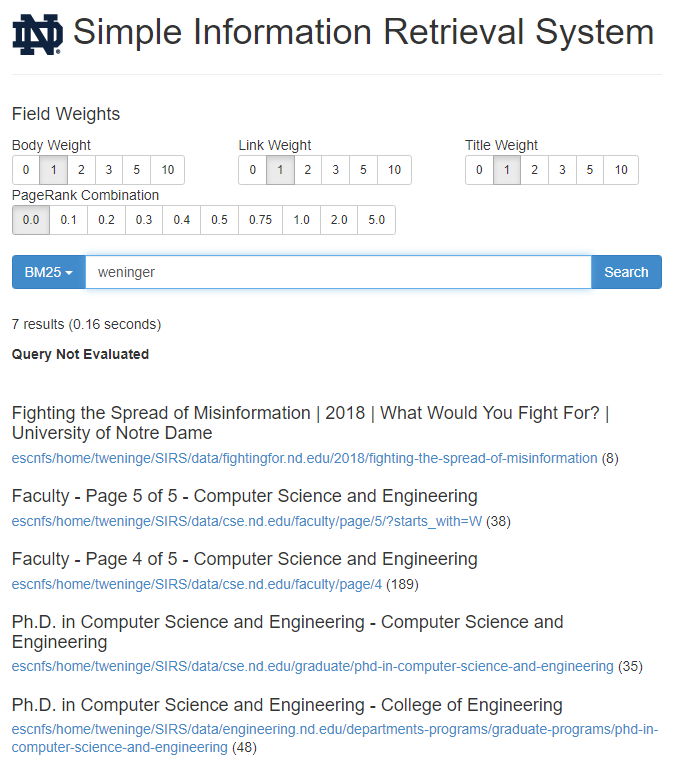
**Make sure to Ctrl+C to close the server when you’ve finished so that others can use your port.
5. 5pts Suppose that three consistency constraints on a database are: 0≤A≤B, 0≤C≤D, and 0≤X≤Y.
Tell whether each of the following independent transactions traces preserves consistency if they were to be executed completely.
- A = A+B; B = A+B;
- D = C+D; C = C+D;
- X = Y+1; Y = X+1;
6. 10 pts For each of the transactions in Question 4, add the read and write actions to the computation and show the effect of the steps on the main memory, disk, and in an UNDO log.
Assume initially that {A,C,X}=3 and {B,D,Y}=12 on disk