- [15 points] Recall that 1 block is 1 disk sector; and 1 disk sector is 4KB (4096 bytes). Let the schema of a table be:
create table midterm_grades ( netid CHAR(8) character set latin1, q1_score TINYINT, q1_comments varchar(100) character set utf8, q2_score TINYINT, q2_comments varchar(100) character set latin1, q3_score TINYINT, q3_comments varchar(100) character set latin1, q4_score TINYINT, q4_comments varchar(100) character set utf8, extra_credit TINYINT )
Let’s say that the average comment length is 20 characters long, and that each record header contains 12 bytes of important record information.
Answer the following questions:
a. How many bytes is does the average record consume? (show your work)
b. About 960 students have taken my databases midterm at Notre Dame (total). Given that records may not span more than one disk sector. How many sectors are needed to store all the midterm records?
2. [15 points] Notice that Q1 did not contain any primary key. If we add a primary key to the netid column, then we will also need to store the index on disk too. Recalculate your answer to Q1-b to take into account a primary key using a B+ Tree on the netid column.
You can use $d$ of either 2 or 170 (or really any number in between so long as you state it clearly and show your work).
3. [30 points] UTF8 encoding is a variable length encoding. This means that sometimes it uses 1 byte, sometimes it uses 2, 3, or 4 bytes to represent a character. How does it know that a character is 1 or 2 or 3 or 4 bytes?
UTF-8 distinguishes this using a unary encoding. That is, if the bits of a character start with 0, then there is only 1 byte being read for this character. 0xxxxxxx represents a 1-byte character (basically the first 127 ascii characters). If the first bits of the character start with 110xxxxx, then there will be two bytes, 1110xxxx means 3 bytes, and 11110xxx means 4 bytes. See this table for example.
| Bytes | 1st byte | 2nd byte | 3rd byte | 4th byte |
|---|---|---|---|---|
| 1 | 0xxxxxxx | |||
| 2 | 110xxxxx | 10xxxxxx | ||
| 3 | 1110xxxx | 10xxxxxx | 10xxxxxx | |
| 4 | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |
Hence, the capital ‘A’, which is 65 in decimal/ASCII is represented as 01000001 encoded as ‘A’ in UTF-8.
The winky emoji: 😉 is 128,521 in decimal which is 00000001 11110110 00001001 in binary, which is encoded into UTF8 as 11110000 10011111 10011000 10001001 (with only 21 encoded bits)
“Encoding errors” happen when a file encoded in one format is decoded in another format:
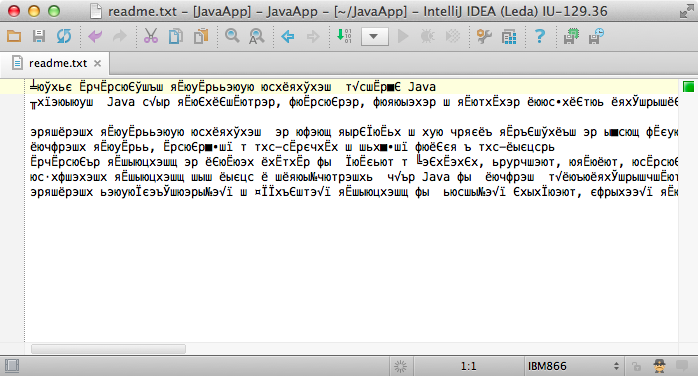
Let’s work to understand what’s happening here.
a. Let’s say that the string ‘Hi’ was encoded with ASCII.
where H is represented in decimal as 72 and
where i is represented in decimal as 105
How would it appear if decoded in UTF8?
b. Let’s say that the string ‘数据库’ (which is Chinese Shùjùkù which translates to “Database” in English is encoded with UTF-8
where 数 is represented in decimal as 25968 and
where 据 is represented in decimal as 25454 and
where 库 is represented in decimal as 24211
(according to https://www.compart.com/)
How would it appear if decoded with Latin-encoding (i.e., ASCII)? (show your work)
4. [20 points] Let $d$=2. Place the data from the price of the table below into a B+ tree indexing on the following table:
| model | speed | ram | hd | price |
|---|---|---|---|---|
| 1001 | 2.66 | 4096 | 250 | 2114 |
| 1002 | 2.10 | 2048 | 250 | 995 |
| 1003 | 1.42 | 2048 | 80 | 478 |
| 1004 | 2.80 | 4096 | 250 | 649 |
| 1005 | 3.20 | 2048 | 250 | 630 |
| 1006 | 3.20 | 4096 | 320 | 1049 |
| 1007 | 2.20 | 4096 | 200 | 510 |
| 1008 | 2.20 | 8192 | 250 | 770 |
| 1009 | 2.00 | 4096 | 250 | 650 |
| 1010 | 2.80 | 8192 | 300 | 770 |
| 1011 | 1.86 | 8192 | 160 | 959 |
| 1012 | 2.80 | 4096 | 160 | 649 |
| 1013 | 3.06 | 2048 | 80 | 529 |
5. [0 points] Get to work on Stage 3 Demo!