Now we need to start talking about how the database is stored and accessed from the disk.
Indexing
types of indexes
B+ trees
hash tables
We can learn how to build an index, but before we do that:
IN CLASS – Question: What is an index? Give examples of an index in real life:
An index on a file speeds up selections on the search key field(s)
Search key = any subset of the fields of a relation
Search key is not the same as key (minimal set of fields that uniquely identify a record in a relation).
Entries in an index: (k, r), where:
$k$ = the key
$r$ = the record OR record id OR record ids
Types of Indexes
Clustered/unclustered
Clustered = records sorted in the key order
Unclustered = no
Dense/sparse
Dense = each record has an entry in the index
Sparse = only some records have
Primary/secondary
Primary = on the primary key
Secondary = on any key
Some textbooks interpret these differently
B+ tree / Hash table / quad tree….
What types of indexes have you learned in data structures?
Files are stored in blocks on disk
Records and blocks –
Examples
Clustered Indexes
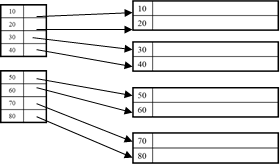
Clustered: File is sorted on the index attribute
Dense: sequence of (key,pointer) pairs
***How much space on disk? N * sizeof(type) * sizeof(ptr). Pointer is 64 bits = 8 bytes.
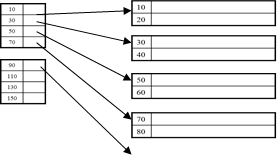
Clustered, Sparse index: one key per data block
***How much space on disk? N * sizeof(type) + sizeof(ptr)*#blocks_with_data
Duplicate keys? Then how do we do it?
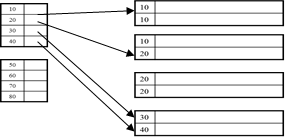
Duplicate, Clustered, Sparse index: Pointer to lowest new search key in each block:
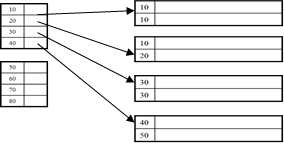
Unclustered Indexes
Often for indexing other attributes than primary key
Always dense (why ?)
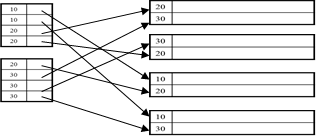
…Because primary key is sorted, and because every table should have a primary key.
Clustered vs Unclustered:
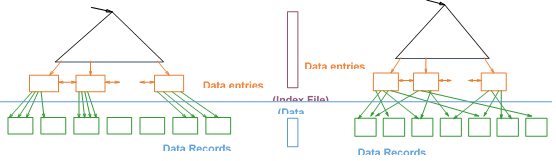
Composite Search Keys
Composite Search Keys: Search on a combination of fields.
Equality query: Every field value is equal to a constant value. E.g. wrt <sal,age> index:
age=20 and sal =75
Range query: Some field value is not a constant. E.g.:
age =20; or age=20 and sal > 10
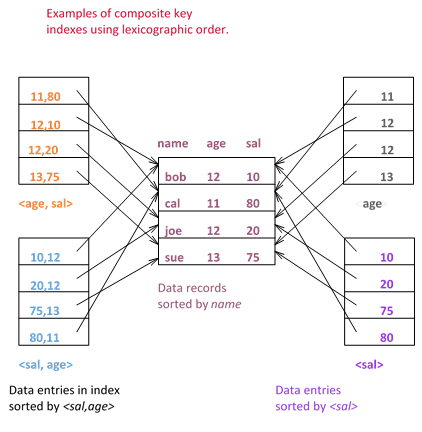
Column Order
Column order of an index is important
Data name
Index age, sal
What would happen if we searched for a column $y$ on a multi-key index $<x,y>$