Data Model:
Files
A file is a bag of (key, value) pairs
Map-Reduce
Input: a bag of (inputkey, value) pairs
Output: a bag of (outputkey, value) pairs
Step 1: Map
User provides the map function
System applies map function in parallel to all (inputkey, value) pairs in the input file (split on HDFS)
- Input: one (inputkey, value)
- Output: bag of (intermediate key, value) pairs
Step 2: Reduce
User provides Reduce function
- Input: (intermediate key, bag of values)
- Output: bag of output values
System groups all pairs with same intermediate key and passes the bag of values to the reduce function
MapReduce
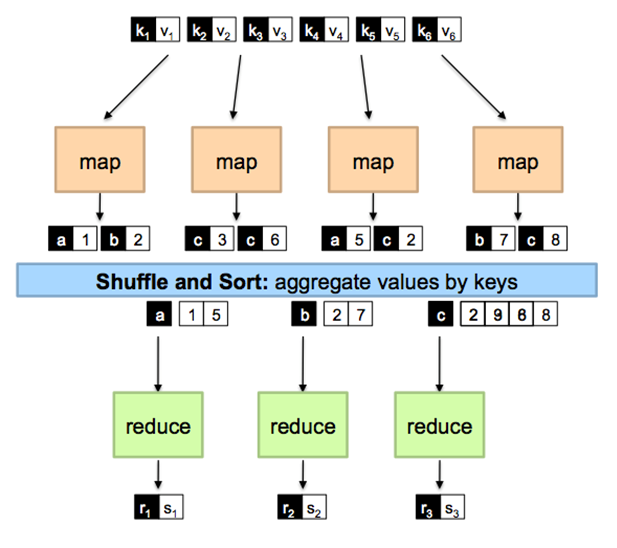
- Input, which is split into 4 servers, each with its own mapper.
- Mapper output goes to combiners (a combiner is like a local reducer)
- Partitioner separates on the keys
- Shuffle and sort merges the key-value pairs on their keys
- Reducer takes key->list[value] pairs and performs some aggregation option.
Example:
Counting the number of occurrences of each word in a large table/file
Let’s work through this: Say we have 3 Hadoop Servers with 2 tuples:
(A, we like toast)
(B, toast is like bread)
Where is A stored? Perhaps it’s split onto different disks via HDFS. Same with B.
Server1 Server2 Server3 (A, We like) (B, toast is) (A, toast) (B, like) (B, bread)
Map function:
map(int key, string value): //key: primary key //value: text contents of column for each word w in contents: emit(w, 1);
Map
Server1 Server2 Server3 (A, We like) (B, toast is) (A, toast) (B, like) (B, bread)
Output?
Emit(‘we’, 1) Emit(‘toast’, 1) Emit(‘toast’, 1)
Emit(‘like’, 1) Emit(‘is’, 1) Emit(‘bread’, 1)
Emit(‘like’, 1)
This goes to the Hadoop subsystem which shuffles, sorts and compiles into a list for reducing.
Reduce
Server1 Server2 Server3 (‘we’, [1]) (‘like’, [1,1]) (‘toast’, [1,1]) (‘is’, [1]) (‘bread’, [1])
Reduce(string key, list<int> values):
// key: a word
// values: a list of counts
int result = 0;
for each v in values:
result += v;
Emit(key, result);
Result:
Emit(‘we’ 1) Emit(‘like’ 2) Emit(‘toast’ 2)
Emit(‘is’ 1) Emit(‘bread’ 1)
Let’s say this is a database
Webpages(docid, word) ---f(x)--> Result(word, cnt)
How would you express f(x) via SQL?
SELECT word, count(word) from Webpages group by word;
Another Example
Server1 Server2 Server3 (South Bend, STJ, 9) (Goshen, ELK, 1) (Elkhart, ELK, 4) (Mishawaka, STJ, 4) (Granger, STJ, 1)
Compute the mean for each county:

Map
Server1 Server2 Server3 (South Bend, STJ, 9) (Goshen, ELK, 1) (Elkhart, ELK, 4) (Mishawaka, STJ, 4) (Granger, STJ, 1)
Emit(‘STJ’, 9) Emit(‘ELK’, 1) Emit(‘ELK’, 4)
Emit(‘STJ’, 4) Emit(‘STJ’, 1)
This goes to the Hadoop subsystem which shuffles, sorts and compiles into a list for reducing
Reduce
Server1 Server2 Server3
('STJ', [9,4,1]) ('ELK', [1,4])
Result
Server1 Server2 Server3
('STJ', 4.67) ('ELK', 2.5)