When we design a database there is a process:
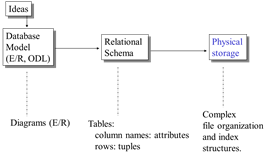
ER vs Relational Model
Both are used to model data
ER model has many concepts
- entities, relations, attributes, etc.
- well-suited for capturing the app. requirements
- not well-suited for computer implementation
- (does not even have operations on its structures)
Relational model
- has just a single concept: relation
- world is represented with a collection of tables/relation
It is well-suited for efficient manipulations on computers
The Basics
Each attribute has a type
Must be atomic type (why? see later)
Called the domain
* Integer
* String
* Real number
Schemas vs. Instances
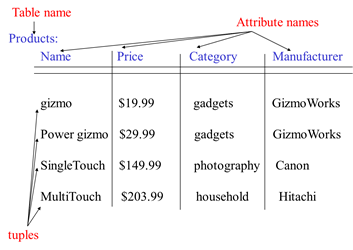
The Schema of a Relation:
Relation name plus attribute names E.g. Product(Name, Price, Category, Manufacturer)
In practice we add the domain for each attribute
The Schema of a Database
A set of relation schemas
- Products(Name, Price, Category, Manufacturer),
- Vendors(Name, Address, Phone),
Relational schema = $R(a_1,\ldots,a_k)$:
Instance = relation with $k$ attributes (of “type” $R$) and values of corresponding domains
Database schema = $R_1(\ldots), R_2(\ldots), \ldots, R_n(\ldots)$
Instance = $n$ relations, of types $R_1, R_2, \ldots, R_n$
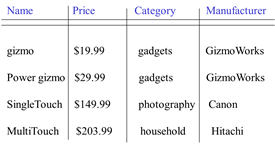
Relational schema: Products(Name, Price, Category, Manufacturer)
Instance =
Updates
The database maintains a current database state.
Updates to the data:
1) add a tuple
2) delete a tuple
3) modify an attribute in a tuple
Updates to the data happen very frequently.
Updates to the schema: relatively rare. Rather painful. Why?
Defining a database schema
A database schema comprises declarations for the relations (“tables”) of the database.
Many other kinds of elements may also appear in the database schema, including views, indexes, and triggers, which we’ll introduce later.
Simplest form is:
CREATE TABLE <name> (
<list of elements>);
And you may remove a relation from the database schema by:
DROP TABLE <name>;
Elements of Table Declarations
The principal element is a pair consisting of an attribute and a type.
The most common types are:
- INT or INTEGER (synonyms).
- REAL or FLOAT (synonyms).
- CHAR($n$) = fixed-length string of $n$ characters.
- VARCHAR($n$) = variable-length string of up to $n$ characters.
CREATE TABLE Groceries (
name CHAR(20),
SKU VARCHAR(20),
price REAL );
DATE and TIME are types in SQL.
The form of a date value is: DATE ‘yyyy-mm-dd’
Example: DATE ‘2023-09-30’ for Sept. 30, 2023.
The form of a time value is: TIME ‘hh:mm:ss’ with an optional decimal point and fractions of a second following.
Example: TIME ’15:30:02.5’ = two and a half seconds after 3:30PM.
Declaring Keys
An attribute or list of attributes may be declared PRIMARY KEY or UNIQUE.
These each say the attribute(s) so declared functionally determine all the attributes of the relation schema.
CREATE TABLE Groceries (
name CHAR(20) PRIMARY KEY,
SKU VARCHAR(20) UNIQUE,
price REAL);
Declaring Multiattribute Keys
A key declaration can also be another element in the list of elements of a CREATE TABLE statement.
This form is essential if the key consists of more than one attribute.
May be used even for one-attribute keys.
CREATE TABLE Groceries (
name CHAR(20),
SKU VARCHAR(20),
price REAL,
PRIMARY KEY (name, SKU));
However, standard SQL requires these distinctions:
- There can be only one
PRIMARY KEYfor a relation, but several UNIQUE attributes. - No attribute of a
PRIMARY KEYcan ever beNULLin any tuple. But attributes declaredUNIQUEmay haveNULL’s, and there may be several tuples withNULL.
Other declarations for attributes:
Two other declarations we can make for an attribute are:
NOT NULLmeans that the value for this attribute may never be NULL.DEFAULT <value>says that if there is no specific value known for this attribute’s component in some tuple, use the stated <value>.
CREATE TABLE Companies (
name CHAR(20) PRIMARY KEY,
address VARCHAR(20) default ‘123 Angela Drive’,
phone VARCHAR(10),
license VARCHAR(15) not null default ‘0’);
Effects of defaults
Suppose we insert the fact that Linebacker is a Company, but we know neither the address nor the phone.
An INSERT with a partial list of attributes makes the insertion possible:
INSERT INTO Companies(name)
VALUES(‘Linebacker’);
What tuple appears?
| Name | address | phone | License |
|---|---|---|---|
| Linebacker | 123 Angela Drive | NULL | 0 |
How big is the tuple?
Name = 20*1byte address = 1byte + 16chars*1byte phone = 4+0 license= 1+1*1
Declare a table schema of Person with five attributes and their properties in SQL.
How big is the tuple on the board?
Adding attributes
We may change a relation schema by adding a new attribute (“column”) by:
ALTER TABLE <name> ADD/MODIFY <attribute declaration>;
Example:
ALTER TABLE Companies ADD phone VARCHAR(10) DEFAULT ‘unlisted’;
ALTER TABLE Companies MODIFY phone VARCHAR(10) DEFAULT ‘unlisted’;
INSERT INTO Companies(name)
VALUES(‘Corbys’);
Remove an attribute from a relation schema by:
ALTER TABLE <name> DROP <attribute>;
Example: we don’t really need the license attribute for bars:
ALTER TABLE Companies DROP phone;
What happens if we alter table to add a UNIQUE attribute, but there are duplicate values?
ALTER TABLE companies MODIFY license varchar(15) unique;
error 1062 duplicates found
What happens if we alter table to add a PRIMARY KEY attribute, but there are null entites?
ALTER TABLE companies DROP PRIMARY KEY
alter table companies add newcol varchar(20);
alter table companies add primary key(newcol);
ERROR 1062 (23000): Duplicate entry '' for key 'PRIMARY'